
1. Introduction
1.1 Project Description
This is a pre-study for a larger audiovisual speech synthesis project that is planned to be carried out during 1998-2000 at Helsinki University of Technology. The main objective of this report is to map the situation of today's speech synthesis technology and to focus on potential methods for the future of this project. Usually literature and articles in the area are focused on a single method or single synthesizer or the very limited range of the technology. In this report the whole speech synthesis area with as many methods, techniques, applications, and products as possible is under investigation. Unfortunately, this leads to a situation where in some cases very detailed information may not be given here, but may be found in given references.
The objective of the whole project is to develop high quality audiovisual speech synthesis with a well synchronized talking head, primarily in Finnish. Other aspects, such as naturalness, personality, platform independence, and quality assessment are also under investigation. Most synthesizers today are so called stand-alones and they do not work platform independently and usually do not share common parts, thus we can not just put together the best parts of present systems to make a state-of-the-art synthesizer. Hence, with good modularity characteristics we may achieve a synthesis system which is easier to develop and improve.
The report starts with a brief historical description of different speech synthesis methods and speech synthesizers. The next chapter includes a short theory section of human speech production, articulatory phonetics, and some other related concepts. The speech synthesis procedure involves lots of different kinds of problems described in Chapter 4. Various existing methods and algorithms are discussed in Chapter 5 and the following two chapters are dedicated to applications and some application frameworks. The latest hot topic in the speech synthesis area is to include facial animation into synthesized speech. A short introduction to audiovisual speech synthesis is included in Chapter 8. Although the audiovisual synthesis is not the main purpose of this report, it will be discussed briefly to give a general view of the project. A list of available synthesizers and some ongoing speech synthesis projects is introduced in Chapter 9 and, finally, the last two chapters contain some evaluation methods, evaluations, and future discussion. The end of the thesis contains a collection of some speech synthesis related literature, WEB-sites, and some sound examples stored on an accompanying audio compact disc.
1.2 Introduction to Speech Synthesis
Speech is the primary means of communication between people. Speech synthesis, automatic generation of speech waveforms, has been under development for several decades (Santen et al. 1997, Kleijn et al. 1998). Recent progress in speech synthesis has produced synthesizers with very high intelligibility but the sound quality and naturalness still remain a major problem. However, the quality of present products has reached an adequate level for several applications, such as multimedia and telecommunications. With some audiovisual information or facial animation (talking head) it is possible to increase speech intelligibility considerably (Beskow et al. 1997). Some methods for audiovisual speech have been recently introduced by for example Santen et al. (1997), Breen et al. (1996), Beskow (1996), and Le Goff et al. (1996).
The text-to-speech (TTS) synthesis procedure consists of two main phases. The first one is text analysis, where the input text is transcribed into a phonetic or some other linguistic representation, and the second one is the generation of speech waveforms, where the acoustic output is produced from this phonetic and prosodic information. These two phases are usually called as high- and low-level synthesis. A simplified version of the procedure is presented in Figure 1.1. The input text might be for example data from a word processor, standard ASCII from e-mail, a mobile text-message, or scanned text from a newspaper. The character string is then preprocessed and analyzed into phonetic representation which is usually a string of phonemes with some additional information for correct intonation, duration, and stress. Speech sound is finally generated with the low-level synthesizer by the information from high-level one.
Fig. 1.1. Simple text-to-speech synthesis procedure.
The simplest way to produce synthetic speech is to play long prerecorded samples of natural speech, such as single words or sentences. This concatenation method provides high quality and naturalness, but has a limited vocabulary and usually only one voice. The method is very suitable for some announcing and information systems. However, it is quite clear that we can not create a database of all words and common names in the world. It is maybe even inappropriate to call this speech synthesis because it contains only recordings. Thus, for unrestricted speech synthesis (text-to-speech) we have to use shorter pieces of speech signal, such as syllables, phonemes, diphones or even shorter segments.
Another widely used method to produce synthetic speech is formant synthesis which is based on the source-filter-model of speech production described in Figure 1.2 below. The method is sometimes called terminal analogy because it models only the sound source and the formant frequencies, not any physical characteristics of the vocal tract (Flanagan 1972). The excitation signal could be either voiced with fundamental frequency (F0) or unvoiced noise. A mixed excitation of these two may also be used for voiced consonants and some aspiration sounds. The excitation is then gained and filtered with a vocal tract filter which is constructed of resonators similar to the formants of natural speech.
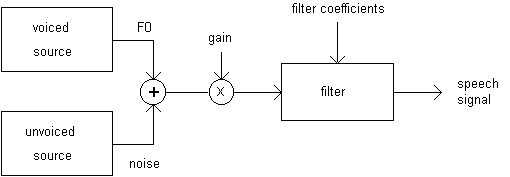
Fig. 1.2. Source-filter model of speech.
In theory, the most accurate method to generate artificial speech is to model the human speech production system directly (O'Saughnessy 1987, Witten 1982, Donovan 1996). This method, called articulatory synthesis, typically involves models of the human articulators and vocal cords. The articulators are usually modeled with a set of area functions of small tube sections. The vocal cord model is used to generate an appropriate excitation signal, which may be for example a two-mass model with two vertically moving masses (Veldhuis et al. 1995). Articulatory synthesis holds a promise of high-quality synthesized speech, but due to its complexity the potential has not been realized yet.
All synthesis methods have some benefits and problems of their own and it is quite difficult to say which method is the best one. With concatenative and formant synthesis, very promising results have been achieved recently, but also articulatory synthesis may arise as a potential method in the future. Different synthesis methods, algorithms, and techniques are discussed more closely in Chapter 5.