8. Audiovisual Speech Synthesis
8.1 Introduction and History
Speech communication relies not only on audition, but also on visual information. Facial movements, such as smiling, grinning, eye blinking, head nodding, and eyebrow rising give an important additional information of the speaker's emotional state. The emotional state may be even concluded from facial expression without any sound (Beskow 1996). Fluent speech is also emphasized and punctuated by facial expressions (Waters et al. 1993). With visual information added to synthesized speech it is also possible to increase the intelligibility significantly, especially when the auditory speech is degraded by for example noise, bandwidth filtering, or hearing impairment (Cohen et al. 1993, Beskow 1996, Le Goff et al. 1996). The visual information is especially helpful with front phonemes whose articulation we can see, such as labiodentals and bilabials (Beskow et al. 1997). For example, intelligibility between /b/ and /d/ increases significantly with visual information (Santen et al. 1997). Synthetic face also increases the intelligibility with natural speech. However, the facial gestures and speech must be coherent. Without coherence the intelligibility of speech may be even decreased. For example, an interesting phenomenon with separate audio and video is so called McGurk effect. If an audio syllable /ba/ is dubbed onto a visual /ga/, it is perceived as /da/ (Cohen et al. 1993, Cole et al. 1995).
Human facial expression has been under investigation for more than one hundred years. The first computer-based modeling and animations were made over 25 years ago. In 1972 Parke introduced the first three-dimensional face model and in 1974 he developed the first version of his famous parameteric three-dimensional model (Santen et al. 1997). Since the computer capabilities have increased rapidly during last decades, the development of facial animation has been also very fast, and will remain fast in the future when the users are becoming more comfortable with the dialogue situations with machines.
Facial animation has been applied to synthetic speech for about ten years. Most of the present audiovisual speech synthesizers are based on a parametric face model presented by Parke in 1982. The model consisted of a mesh of about 800 polygons that approximated the surface of a human face including the eyes, the eyebrows, the lips, and the teeth. The polygon surface was controlled by using 50 parameters (Beskow 1996). However, present systems contain a number of modifications to Parke model to improve it and to make it more suitable for synthesized speech. These are usually a set of rules for generating facial control parameter trajectories from phonetic text, and a simple tongue model, which were not included in the original Parke model.
Audiovisual speech synthesis may be used in several applications. Additional visual information is very helpful for hearing impaired people. It can be used as a tool for interactive training of speechreading. Also a face with semi-transparent skin and a well modeled tongue can be used to visualize tongue positions in speech training for deaf children (Beskow 1996). It may be used in information systems in public and noisy environments, such as airports, train stations and shopping centers. If it is possible to make the talking head look like some certain individual, it may be utilized in videoconferencing or used as a synthetic newsreader. Multimedia is also an important application field of talking heads. A full synthetic story teller requires considerably less storage capacity compared to for example movie clips.
8.2 Techniques and Models
Perhaps the easiest approach for audiovisual speech is to use pre-stored images to represent all the possible shapes under interest and combine these with for example some morphing method similar to concatenative speech synthesis. This method may be quite successful for some limited applications, but is very inflexible, since there is no way to control different facial features independently of each other (Beskow 1996). Because of this, the talking head is usually implemented with some kind of parametric model. There are two usually used basic methods:
Due to difficulties with muscle based implementation, most researchers have found the parametric model more feasible (Beskow 1996, Le Goff et al. 1996) and most of the present systems are using a parametric model descended from Parke model. Naturally, the mouth and the lips are the most important in facial models, but with eyes, eyebrows, jaw, and tongue it is possible to make the audiovisual speech more natural and intelligible (Santen et al. 1997).
In visual part, the equivalence of phonemes is called as visemes. One example of how the set of visemes can be formed from phonemes of standard English is represented in Table 8.1. The phonetic SAM-PA representation which has been used is described earlier in Chapter 4. Certainly, due to articulation effect, this set of visemes is not enough to represent accurate mouth shapes (Breen et al. 1996).
Table 8.1. Set of visemes formed by phonemes of standard British English.
|
Viseme group | Phonemes (SAM-PA) |
| Consonant 1 | p, b, m |
| Consonant 2 | f, v |
| Consonant 3 | D, T |
| Consonant 4 | s, z |
| Consonant 5 | S, Z |
| Consonant 6 | t, d, n, l, r |
| "Both" | w, U, u, O |
| Vowel 1 | Q, V, A |
| Vowel 2 | 3, i, j |
| Vowel 3 | @ , E, I, { |
Like in concatenative speech synthesis, diphone-like units may be used to avoid discontinuities and to include coarticulation effect in used units. In visual part, these units are called as di-visemes. A di-viseme records the change in articulation produced when moving from one viseme to another. The number of video recordings with di-visemes is 128 and may be reduced to less than 50 if the further approximation is made that the coarticulation due to vowel production greatly outweighs the effects produced by consonants (Breen et al. 1996). Longer units may also be used, such as tri-visemes which contains the immediate right and left context effect on a center viseme. However, the number of needed video recordings is approximately 800, which is clearly unrealistic.
Audiovisual speech suffers mostly of the same problems as normal speech synthesis. For example, phoneme /t/ in tea differs in lip shape to the same phoneme in two, and Finnish phoneme /k/ in kissa and koira is visually very different compared to acoustical difference. These differences in facial movements due to context are the visual correlate of the speech effect known as coarticulation (Breen et al. 1996).
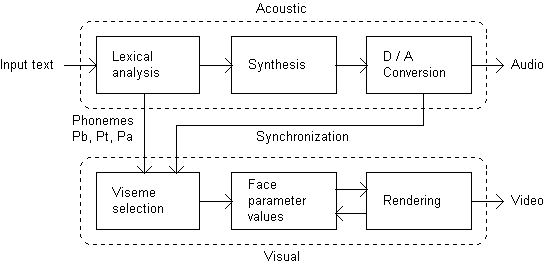
The speech synthesizer and the facial animation are usually two different systems and they must be synchronized somehow. If the synchronization process is not done properly, the quality and intelligibility of audiovisual speech may even decrease significantly. Usually, the speech synthesizer is used to provide the information for controlling the visual part. The computational requirements for the visual part are usually considerably higher than for the audio, so some kind of feedback from the visual part may be needed to avoid lag between audio and video. The lag may be avoided by buffering the audio images and adjusting the frame rate if necessary. The structure of an audiovisual speech synthesizer is presented in Figure 8.1.
Fig. 8.1. Structure of the audiovisual synthesizer.
The sequence to control the visual synthesizer is processed as three phoneme frames: the target phoneme (Pt), the phoneme before (Pb) and the one after the target (Pa). The transformation from phonetic representation to the face parameter values is based on corresponding visemes.