4. Problems in Speech Synthesis
The problem area in speech synthesis is very wide. There are several problems in text pre-processing, such as numerals, abbreviations, and acronyms. Correct prosody and pronunciation analysis from written text is also a major problem today. Written text contains no explicit emotions and pronunciation of proper and foreign names is sometimes very anomalous. At the low-level synthesis, the discontinuities and contextual effects in wave concatenation methods are the most problematic. Speech synthesis has been found also more difficult with female and child voices. Female voice has a pitch almost twice as high as with male voice and with children it may be even three times as high. The higher fundamental frequency makes it more difficult to estimate the formant frequency locations (Klatt 1987, Klatt et al. 1990). The evaluation and assessment of synthesized speech is neither a simple task. Speech quality is a multidimensional term and the evaluation method must be chosen carefully to achieve desired results. This chapter describes the major problems in text-to-speech research.
4.1 Text-to-Phonetic Conversion
The first task faced by any TTS system is the conversion of input text into linguistic representation, usually called text-to-phonetic or grapheme-to-phoneme conversion. The difficulty of conversion is highly language depended and includes many problems. In some languages, such as Finnish, the conversion is quite simple because written text almost corresponds to its pronunciation. For English and most of the other languages the conversion is much more complicated. A very large set of different rules and their exceptions is needed to produce correct pronunciation and prosody for synthesized speech. Some languages have also special features which are discussed more closely at the end of this chapter. Conversion can be divided in three main phases, text preprocessing, creation of linguistic data for correct pronunciation, and the analysis of prosodic features for correct intonation, stress, and duration.
4.1.1 Text preprocessing
Text preprocessing is usually a very complex task and includes several language dependent problems (Sproat 1996). Digits and numerals must be expanded into full words. For example in English, numeral 243 would be expanded as two hundred and forty-three and 1750 as seventeen-fifty (if year) or one-thousand seven-hundred and fifty (if measure). Related cases include the distinction between the 747 pilot and 747 people. Fractions and dates are also problematic. 5/16 can be expanded as five-sixteenths (if fraction) or May sixteenth (if date). Expansion ordinal numbers have been found also problematic. The first three ordinals must be expanded differently than the others, 1st as first, 2nd as second, and 3rd as third. Same kind of contextual problems are faced with roman numerals. Chapter III should be expanded as Chapter three and Henry III as Henry the third and I may be either a pronoun or number. Roman numerals may be also confused with some common abbreviations, such as MCM. Numbers may also have some special forms of expression, such as 22 as double two in telephone numbers and 1-0 as one love in sports.
Abbreviations may be expanded into full words, pronounced as written, or pronounced letter by letter (Macon 1996). There are also some contextual problems. For example kg can be either kilogram or kilograms depending on preceding number, St. can be saint or street, Dr. doctor or drive and ft. Fort, foot or feet. In some cases, the adjacent information may be enough to find out the correct conversion, but to avoid misconversions the best solution in some cases may be the use of letter-to-letter conversion. Innumerable abbreviations for company names and other related things exists and they may be pronounced in many ways. For example, N.A.T.O. or RAM are usually pronounced as written and SAS or ADP letter-by-letter. Some abbreviations such as MPEG as empeg are pronounced irregularly.
Special characters and symbols, such as '$', '%', '&', '/', '-', '+', cause also special kind of problems. In some situations the word order must be changed. For example, $71.50 must be expanded as seventy-one dollars and fifty cents and $100 million as one hundred million dollars, not as one hundred dollars million. The expression '1-2' may be expanded as one minus two or one two, and character '&' as et or and. Also special characters and character strings in for example web-sites or e-mail messages must be expanded with special rules. For example, character '@ ' is usually converted as at and e-mail messages may contain character strings, such as some header information, which may be omitted. Some languages also include special non ASCII characters, such as accent markers or special symbols.
Written text may also be constructed in several ways, like in several columns and pages as in a normal newspaper article. This may cause insuperable problems especially with optical reading machines.
In Finnish, the text preprocessing scheme is in general easier but contains also some specific difficulties. Especially with numerals and ordinals expansion may be even more difficult than in other languages due to several cases constructed by several different suffixes. The two first ordinals must be expanded differently in some cases and with larger numbers the expansion may become rather complex. With digits, roman numerals, dates, and abbreviations same kind of difficulties are faced as in other languages. For example, for Roman numerals I and III, there is at least three possible conversion. Some examples of the most difficult abbreviations are given in Table 4.1. In most cases, the correct conversion may be concluded from the type of compounding characters or from other compounding information. But to avoid misconversions, some abbreviations must be spelled letter-by-letter.
Table 4.1. Some examples of the text parsing difficulties for Finnish in some contexts.
|
Text |
Different possibilities in different contexts |
|
s |
sekuntia, sivua, syntynyt |
|
kg |
(1) kilogramma, (2) kilogrammaa |
|
III |
kolmos (olut), (Kaarle) kolmas, (luku) kolme |
|
mm |
millimetriä, muun muassa |
|
min |
minimi, minuuttia |
|
huom |
huomenna, huomio |
|
kk |
kuukausi, kuukautta, keittokomero |
|
os. |
osoite, omaa sukua, osasto |
In Finnish the conversion of common numbers is probably more complicated than in English. The suffixes, such as s in ordinals are included after every single number. For example ordinal 1023. is pronounced as "tuhannes kahdeskymmenes kolmas". In some cases, the conversion of a number may be concluded from the suffix of the following word, but sometimes the situation may be very ambiguous which can be seen from the following examples:
It is easy to see from previous examples that, for correct conversion in every possible situation, a very complicated set of rules is needed.
4.1.2 Pronunciation
The second task is to find correct pronunciation for different contexts in the text. Some words, called homographs, cause maybe the most difficult problems in TTS systems. Homographs are spelled the same way but they differ in meaning and usually in pronunciation (e.g. fair, lives). The word lives is for example pronounced differently in sentences "Three lives were lost" and "One lives to eat". Some words, e.g. lead, has different pronunciations when used as a verb or noun, and between two noun senses (He followed her lead / He covered the hull with lead). With these kind of words some semantical information is necessary to achieve correct pronunciation.
The pronunciation of a certain word may also be different due to contextual effects. This is easy to see when comparing phrases the end and the beginning. The pronunciation of the depends on the initial phoneme in the following word. Compound words are also problematic. For example the characters 'th' in mother and hothouse is pronounced differently. Some sounds may also be either voiced or unvoiced in different context. For example, phoneme /s/ in word dogs is voiced, but unvoiced in word cats (Allen et al. 1987).
Finding correct pronunciation for proper names, especially when they are borrowed from other languages, is usually one of the most difficult tasks for any TTS system. Some common names, such as Nice and Begin, are ambiguous in capitalized context, including sentence initial position, titles and single text. For example, the sentence Nice is a nice place is very problematic because the word Nice may be pronounced as /niis/ or /nais/. Some names and places have also special pronunciation, such as Leicester and Arkansas. For correct pronunciation, these kind of words may be included in a specific exception dictionary. Unfortunately, it is clear that there is no way to build a database of all proper names in the world.
In Finnish, considerably less rules are needed because in most cases words are pronounced as written. However, few exceptions exists, such as /h / in words kenkä and kengät. Finnish alphabet contains also some foreign origin letters which can be converted in text preprocessing, such as taxi - taksi (x - ks) and pizza (zz - ts). The letter pairs v and w, c and s, or å and o are also usually pronounced the same way (Karjalainen 1978).
4.1.3 Prosody
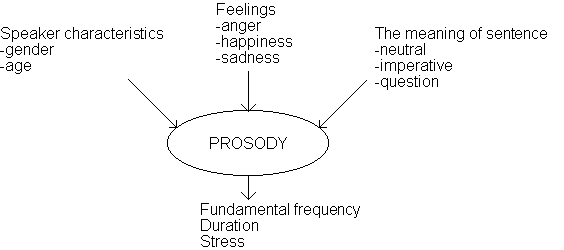
Finding correct intonation, stress, and duration from written text is probably the most challenging problem for years to come. These features together are called prosodic or suprasegmental features and may be considered as the melody, rhythm, and emphasis of the speech at the perceptual level. The intonation means how the pitch pattern or fundamental frequency changes during speech. The prosody of continuous speech depends on many separate aspects, such as the meaning of the sentence and the speaker characteristics and emotions. The prosodic dependencies are shown in Figure 4.1. Unfortunately, written text usually contains very little information of these features and some of them change dynamically during speech. However, with some specific control characters this information may be given to a speech synthesizer.
Timing at sentence level or grouping of words into phrases correctly is difficult because prosodic phrasing is not always marked in text by punctuation, and phrasal accentuation is almost never marked (Santen et al. 1997). If there is no breath pauses in speech or if they are in wrong places, the speech may sound very unnatural or even the meaning of the sentence may be misunderstood. For example, the input string "John says Peter is a liar" can be spoken as two different ways giving two different meanings as "John says: Peter is a liar" or "John, says Peter, is a liar". In the first sentence Peter is a liar, and in the second one the liar is John.
Fig. 4.1. Prosodic dependencies.
4.2 Problems in Low Level Synthesis
There are many methods to produce speech sounds after text and prosodic analysis. All these methods have some benefits and problems of their own.
In articulatory synthesis (see 5.1), the collection of data and implementation of rules to drive that data correctly is very complex. It is almost impossible to model masses, tongue movements, or other characteristics of the vocal system perfectly. Due to this complexity, the computational load may increase considerably.
In formant synthesis (see 5.2), the set of rules controlling the formant frequencies and amplitudes and the characteristics of the excitation source is large. Also some lack of naturalness, especially with nasalized sounds, is considered a major problem with formant synthesis.
In concatenative synthesis (see 5.3), the collecting of speech samples and labeling them is very time-consuming and may yield quite large waveform databases. However, the amount of data may be reduced with some compression method. Concatenation points between samples may cause distortion to the speech. With some longer units, such as words or syllables, the coarticulation effect is a problem and some problems with memory and system requirements may arise.
4.3 Language Specific Problems and Features
For certain languages synthetic speech is easier to produce than in others. Also, the amount of potential users and markets are very different with different countries and languages which also affects how much resources are available for developing speech synthesis. Most of languages have also some special features which can make the development process either much easier or considerably harder.
Some languages, such as Finnish, Italian, and Spanish, have very regular pronunciation. Sometimes there is almost one-to-one correspondence with letter to sound. The other end is for example French with very irregular pronunciation. Many languages, such as French, German, Danish and Portuguese also contain lots of special stress markers and other non ASCII characters (Oliveira et al. 1992). In German, the sentential structure differs largely from other languages. For text analysis, the use of capitalized letters with nouns may cause some problems because capitalized words are usually analyzed differently than others.
In Japanese, almost every spoken syllable is in CV form which makes the synthesis a bit easier than with other languages. On the other hand, conversion from Kanji to Kana symbols must be performed when using a TTS system (Hirokawa 1989). In Chinese and many other Asian languages which are based on non ASCII alphabet, words are not delimited with whitespace (space, tab etc.) and word boundaries must therefore be reconstructed for such languages separately (Santen et al. 1997). However, these languages usually contain a designated symbol as sentence delimiter which makes the end-of-the-sentence detection easier, unlike in English where the period may be the sentence delimiter or used to mark abbreviation (Kleijn et al. 1998). In some tone languages, such as Chinese, the intonation may be even used to change the meaning of the word (Breen 1992).