
5. Methods, Techniques, and Algorithms
Synthesized speech can be produced by several different methods. All of these have some benefits and deficiencies that are discussed in this and previous chapters. The methods are usually classified into three groups:
The formant and concatenative methods are the most commonly used in present synthesis systems. The formant synthesis was dominant for long time, but today the concatenative method is becoming more and more popular. The articulatory method is still too complicated for high quality implementations, but may arise as a potential method in the future.
5.1 Articulatory Synthesis
Articulatory synthesis tries to model the human vocal organs as perfectly as possible, so it is potentially the most satisfying method to produce high-quality synthetic speech. On the other hand, it is also one of the most difficult methods to implement and the computational load is also considerably higher than with other common methods (Kröger 1992, Rahim et al. 1993). Thus, it has received less attention than other synthesis methods and has not yet achieved the same level of success.
Articulatory synthesis typically involves models of the human articulators and vocal cords. The articulators are usually modeled with a set of area functions between glottis and mouth. The first articulatory model was based on a table of vocal tract area functions from larynx to lips for each phonetic segment (Klatt 1987). For rule-based synthesis the articulatory control parameters may be for example lip aperture, lip protrusion, tongue tip height, tongue tip position, tongue height, tongue position and velic aperture. Phonatory or excitation parameters may be glottal aperture, cord tension, and lung pressure (Kröger 1992).
When speaking, the vocal tract muscles cause articulators to move and change shape of the vocal tract which causes different sounds. The data for articulatory model is usually derived from X-ray analysis of natural speech. However, this data is usually only 2-D when the real vocal tract is naturally 3-D, so the rule-based articulatory synthesis is very difficult to optimize due to the unavailability of sufficient data of the motions of the articulators during speech. Other deficiency with articulatory synthesis is that X-ray data do not characterize the masses or degrees of freedom of the articulators (Klatt 1987). Also, the movements of tongue are so complicated that it is almost impossible to model them precisely.
Advantages of articulatory synthesis are that the vocal tract models allow accurate modeling of transients due to abrupt area changes, whereas formant synthesis models only spectral behavior (O'Saughnessy 1987). The articulatory synthesis is quite rarely used in present systems, but since the analysis methods are developing fast and the computational resources are increasing rapidly, it might be a potential synthesis method in the future.
5.2 Formant Synthesis
Probably the most widely used synthesis method during last decades has been formant synthesis which is based on the source-filter-model of speech described in Chapter 2. There are two basic structures in general, parallel and cascade, but for better performance some kind of combination of these is usually used. Formant synthesis also provides infinite number of sounds which makes it more flexible than for example concatenation methods.
At least three formants are generally required to produce intelligible speech and up to five formants to produce high quality speech. Each formant is usually modeled with a two-pole resonator which enables both the formant frequency (pole-pair frequency) and its bandwidth to be specified (Donovan 1996).
Rule-based formant synthesis is based on a set of rules used to determine the parameters necessary to synthesize a desired utterance using a formant synthesizer (Allen et al. 1987). The input parameters may be for example the following, where the open quotient means the ratio of the open-glottis time to the total period duration (Holmes et al. 1990):
A cascade formant synthesizer (Figure 5.1) consists of band-pass resonators connected in series and the output of each formant resonator is applied to the input of the following one. The cascade structure needs only formant frequencies as control information. The main advantage of the cascade structure is that the relative formant amplitudes for vowels do not need individual controls (Allen et al. 1987).
Fig. 5.1. Basic structure of cascade formant synthesizer.
The cascade structure has been found better for non-nasal voiced sounds and because it needs less control information than parallel structure, it is then simpler to implement. However, with cascade model the generation of fricatives and plosive bursts is a problem.
A parallel formant synthesizer (Figure 5.2) consists of resonators connected in parallel. Sometimes extra resonators for nasals are used. The excitation signal is applied to all formants simultaneously and their outputs are summed. Adjacent outputs of formant resonators must be summed in opposite phase to avoid unwanted zeros or antiresonances in the frequency response (O'Saughnessy 1987). The parallel structure enables controlling of bandwidth and gain for each formant individually and thus needs also more control information.
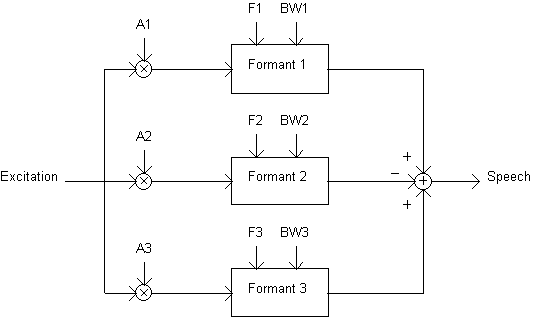
Fig. 5.2. Basic structure of a parallel formant synthesizer.
The parallel structure has been found to be better for nasals, fricatives, and stop-consonants, but some vowels can not be modeled with parallel formant synthesizer as well as with the cascade one.
There has been widespread controversy over the quality and suitably characteristics of these two structures. It is easy to see that good results with only one basic method is difficult to achieve so some efforts have been made to improve and combine these basic models. In 1980 Dennis Klatt (Klatt 1980) proposed a more complex formant synthesizer which incorporated both the cascade and parallel synthesizers with additional resonances and anti-resonances for nasalized sounds, sixth formant for high frequency noise, a bypass path to give a flat transfer function, and a radiation characteristics. The system used quite complex excitation model which was controlled by 39 parameters updated every 5 ms. The quality of Klatt Formant Synthesizer was very promising and the model has been incorporated into several present TTS systems, such as MITalk, DECtalk, Prose-2000, and Klattalk (Donovan 1996). Parallel and cascade structures can also be combined by several other ways. One solution is to use so called PARCAS (Parallel-Cascade) model introduced and patented by Laine (1982) for SYNTE3 speech synthesizer for Finnish. In the model, presented in Figure 5.3, the transfer function of the uniform vocal tract is modeled with two partial transfer functions, each including every second formant of the transfer function. Coefficients k1, k2, and k3 are constant and chosen to balance the formant amplitudes in the neutral vowel to keep the gains of parallel branches constant for all sounds (Laine 1982).
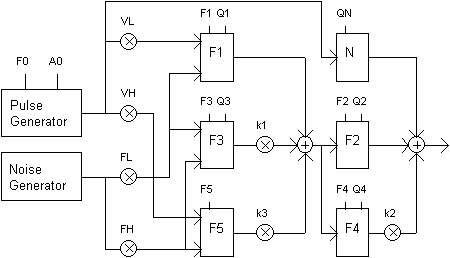
Fig. 5.3. PARCAS model (Laine 1989).
The PARCAS model uses a total of 16 control parameters:
The used excitation signal in formant synthesis consists of some kind of voiced source or white noise. The first voiced source signals used were simple sawtooth type. In 1981 Dennis Klatt introduced more sophisticated voicing source for his Klattalk system (Klatt 1987). The correct and carefully selected excitation is important especially when good controlling of speech characteristics is wanted.
The formant filters represent only the resonances of the vocal tract, so additional provision is needed for the effects of the shape of the glottal waveform and the radiation characteristics of the mouth. Usually the glottal waveform is approximated simply with -12dB/octave filter and radiation characteristics with simple +6dB/octave filter.
5.3 Concatenative Synthesis
Connecting prerecorded natural utterances is probably the easiest way to produce intelligible and natural sounding synthetic speech. However, concatenative synthesizers are usually limited to one speaker and one voice and usually require more memory capacity than other methods.
One of the most important aspects in concatenative synthesis is to find correct unit length. The selection is usually a trade-off between longer and shorter units. With longer units high naturalness, less concatenation points and good control of coarticulation are achieved, but the amount of required units and memory is increased. With shorter units, less memory is needed, but the sample collecting and labeling procedures become more difficult and complex. In present systems units used are usually words, syllables, demisyllables, phonemes, diphones, and sometimes even triphones.
Word is perhaps the most natural unit for written text and some messaging systems with very limited vocabulary. Concatenation of words is relative easy to perform and coarticulation effects within a word are captured in the stored units. However, there is a great difference with words spoken in isolation and in continuos sentence which makes the continuous speech to sound very unnatural (Allen et al. 1987). Because there are hundreds of thousands of different words and proper names in each language, word is not a suitable unit for any kind of unrestricted TTS system.
The number of different syllables in each language is considerably smaller than the number of words, but the size of unit database is usually still too large for TTS systems. For example, there are about 10,000 syllables in English. Unlike with words, the coarticulation effect is not included in stored units, so using syllables as a basic unit is not very reasonable. There is also no way to control prosodic contours over the sentence. At the moment, no word or syllable based full TTS system exists. The current synthesis systems are mostly based on using phonemes, diphones, demisyllables or some kind of combinations of these.
Demisyllables represents the initial and final parts of syllables. One advantage of demisyllables is that only about 1,000 of them is needed to construct the 10,000 syllables of English (Donovan 1996). Using demisyllables, instead of for example phonemes and diphones, requires considerably less concatenation points. Demisyllables also take account of most transitions and then also a large number of coarticulation effects and also covers a large number of allophonic variations due to separation of initial and final consonant clusters. However, the memory requirements are still quite high, but tolerable. Compared to phonemes and diphones, the exact number of demisyllables in a language can not be defined. With purely demisyllable based system, all possible words can not be synthesized properly. This problem is faced at least with some proper names (Hess 1992). However, demisyllables and syllables may be successfully used in a system which uses variable length units and affixes, such as the HADIFIX system described in Chapter 9 (Dettweiler et al. 1985).
Phonemes are probably the most commonly used units in speech synthesis because they are the normal linguistic presentation of speech. The inventory of basic units is usually between 40 and 50, which is clearly the smallest compared to other units (Allen et al. 1987). Using phonemes gives maximum flexibility with the rule-based systems. However, some phones that do not have a steady-state target position, such as plosives, are difficult to synthesize. The articulation must also be formulated as rules. Phonemes are sometimes used as an input for speech synthesizer to drive for example diphone-based synthesizer.
Diphones (or dyads) are defined to extend the central point of the steady state part of the phone to the central point of the following one, so they contain the transitions between adjacent phones. That means that the concatenation point will be in the most steady state region of the signal, which reduces the distortion from concatenation points. Another advantage with diphones is that the coarticulation effect needs no more to be formulated as rules. In principle, the number of diphones is the square of the number of phonemes (plus allophones), but not all combinations of phonemes are needed. For example, in Finnish the combinations, such as /hs/, /sj/, /mt/, /nk/, and /h p/ within a word are not possible. The number of units is usually from 1500 to 2000, which increases the memory requirements and makes the data collection more difficult compared to phonemes. However, the number of data is still tolerable and with other advantages, diphone is a very suitable unit for sample-based text-to-speech synthesis. The number of diphones may be reduced by inverting symmetric transitions, like for example /as/ from /sa/.
Longer segmental units, such as triphones or tetraphones, are quite rarely used. Triphones are like diphones, but contains one phoneme between steady-state points (half phoneme - phoneme - half phoneme). In other words, a triphone is a phoneme with a specific left and right context. For English, more than 10,000 units are required (Huang et al. 1997).
Building the unit inventory consists of three main phases (Hon et al. 1998). First, the natural speech must be recorded so that all used units (phonemes) within all possible contexts (allophones) are included. After this, the units must be labeled or segmented from spoken speech data, and finally, the most appropriate units must be chosen. Gathering the samples from natural speech is usually very time-consuming. However, some is this work may be done automatically by choosing the input text for analysis phase properly. The implementation of rules to select correct samples for concatenation must also be done very carefully.
There are several problems in concatenative synthesis compared to other methods.
Some of the problems may be solved with methods described below and the use of concatenative method is increasing due to better computer capabilities (Donovan 1996).
5.3.1 PSOLA Methods
The PSOLA (Pitch Synchronous Overlap Add) method was originally developed at France Telecom (CNET). It is actually not a synthesis method itself but allows prerecorded speech samples smoothly concatenated and provides good controlling for pitch and duration, so it is used in some commercial synthesis systems, such as ProVerbe and HADIFIX (Donovan 1996).
There are several versions of the PSOLA algorithm and all of them work in essence the same way. Time-domain version, TD-PSOLA, is the most commonly used due to its computational efficiency (Kortekaas et al. 1997). The basic algorithm consist of three steps (Charpentier et al. 1989, Valbret et. al 1991). The analysis step where the original speech signal is first divided into separate but often overlapping short-term analysis signals (ST), the modification of each analysis signal to synthesis signal, and the synthesis step where these segments are recombined by means of overlap-adding. Short term signals xm(n) are obtained from digital speech waveform x(n) by multiplying the signal by a sequence of pitch-synchronous analysis window hm(n):
xm(n) = hm(tm - n)x(n), (5.1)
where m is an index for the short-time signal. The windows, which are usually Hanning type, are centered around the successive instants tm, called pitch-marks. These marks are set at a pitch-synchronous rate on the voiced parts of the signal and at a constant rate on the unvoiced parts. The used window length is proportional to local pitch period and the window factor is usually from 2 to 4 (Charpentier 1989, Kleijn et al. 1998). The pitch markers are determined either by manually inspection of speech signal or automatically by some pitch estimation methods (Kortekaas et al. 1997). The segment recombination in synthesis step is performed after defining a new pitch-mark sequence.
Manipulation of fundamental frequency is achieved by changing the time intervals between pitch markers (see Figure 5.4). The modification of duration is achieved by either repeating or omitting speech segments. In principle, modification of fundamental frequency also implies a modification of duration (Kortekaas et al. 1997).
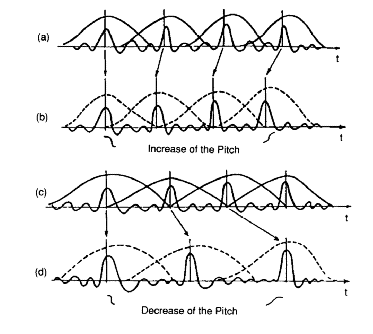
Fig. 5.4. Pitch modification of a voiced speech segment.
Another variations of PSOLA, Frequency Domain PSOLA (FD-PSOLA) and the Linear-Predictive PSOLA (LP-PSOLA), are theoretically more appropriate approaches for pitch-scale modifications because they provide independent control over the spectral envelope of the synthesis signal (Moulines et al. 1995). FD-PSOLA is used only for pitch-scale modifications and LP-PSOLA is used with residual excited vocoders.
Some drawbacks with PSOLA method exists. The pitch can be determined only for voiced sounds and applied to unvoiced signal parts it might generate a tonal noise (Moulines et al. 1990).
5.3.2 Microphonemic Method
The basic idea of the microphonemic method is to use variable length units derived from natural speech (Lukaszewicz et al. 1987). These units may be words, syllables, phonemes (and allophones), pitch periods, transients, or noise segments (Lehtinen et al. 1989). From these segments a dictionary of prototypes is collected.
Prototypes are concatenated in time axis with PSOLA-like method. If the formant distances between consecutive sound segments is less than two critical bandwidths (Barks), the concatenation is made by simple linear amplitude-based interpolation between the prototypes. If the difference is more than two Barks, an extra intermediate prototype must be used because the simple amplitude-based interpolation is not sufficient for perceptually acceptable formant movements (Lukaszewicz et al. 1987). The overlap-add processes of prototypes are shown in Figure 5.5.
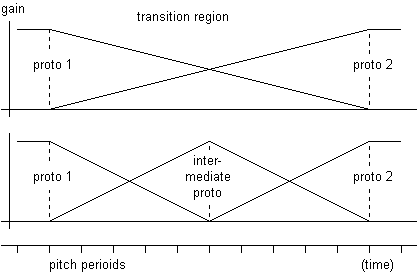
Fig. 5.5. Linear amplitude based interpolation (Lukaszewicz et al. 1997).
Some consonants need special attention. For example, stop consonants can be stored as direct waveform segments as several variants in the different vowel context (Lehtinen et al. 1989). With fricatives, prototypes of about 50 ms of total length and 10 ms units from them are randomly selected for concatenation with the interpolation method above. Most voiced consonants act like vowels, but the context dependence variability is higher (Lukaszewicz et al. 1987).
The benefits of the microphonemic method is that the computational load and storage requirements are rather low compared to other sample based methods (Lehtinen 1990). The biggest problem, as in other sample based methods, is how to extract the optimal collection of prototypes from natural speech and the developing of rules for concatenating them.
5.4 Linear Prediction based Methods
Linear predictive methods are originally designed for speech coding systems, but may be also used in speech synthesis. In fact, the first speech synthesizers were developed from speech coders (see 2.1). Like formant synthesis, the basic LPC is based on the source-filter-model of speech described in Chapter 1. The digital filter coefficients are estimated automatically from a frame of natural speech.
The basis of linear prediction is that the current speech sample y(n) can be approximated or predicted from a finite number of previous p samples y(n-1) to y(n-k) by a linear combination with small error term e(n) called residual signal. Thus,
![]() ,
,
and
![]() ,
,
where ![]() is a predicted value, p is the linear predictor order, and a(k) are the linear prediction coefficients which are found by minimizing the sum of the squared errors over a frame. Two methods, the covariance method and the autocorrelation method, are commonly used to calculate these coefficients. Only with the autocorrelation method the filter is guaranteed to be stable (Witten 1982, Kleijn et al. 1998).
is a predicted value, p is the linear predictor order, and a(k) are the linear prediction coefficients which are found by minimizing the sum of the squared errors over a frame. Two methods, the covariance method and the autocorrelation method, are commonly used to calculate these coefficients. Only with the autocorrelation method the filter is guaranteed to be stable (Witten 1982, Kleijn et al. 1998).
In synthesis phase the used excitation is approximated by a train of impulses for voiced sounds and by random noise for unvoiced. The excitation signal is then gained and filtered with a digital filter for which the coefficients are a(k). The filter order is typically between 10 and 12 at 8 kHz sampling rate, but for higher quality at 22 kHz sampling rate, the order needed is between 20 and 24 (Kleijn et al. 1998, Karjalainen et al. 1998). The coefficients are usually updated every 5-10 ms.
The main deficiency of the ordinary LP method is that it represents an all-pole model, which means that phonemes that contain antiformants such as nasals and nasalized vowels are poorly modeled. The quality is also poor with short plosives because the time-scale events may be shorter than the frame size used for analysis. With these deficiencies the speech synthesis quality with standard LPC method is generally considered poor, but with some modifications and extensions for the basic model the quality may be increased.
Warped Linear Prediction (WLP) takes advantages of human hearing properties and the needed order of filter is then reduced significally, from orders 20-24 to 10-14 with 22 kHz sampling rate (Laine et al. 1994, Karjalainen et al. 1998). The basic idea is that the unit delays in digital filter are replaced by following all-pass sections
![]() ,
,
where l is a warping parameter between -1 and 1 and D1(z) is a warped delay element and with Bark scale it is l = 0.63 with sampling rate of 22 kHz. WLP provides better frequency resolution at low frequencies and worse at high frequencies. However, this is very similar to human hearing properties (Karjalainen et al. 1998).
Several other variations of linear prediction have been developed to increase the quality of the basic method (Childers et al. 1994, Donovan 1996). With these methods the used excitation signal is different from ordinary LP method and the source and filter are no longer separated. These kind of variations are for example multipulse linear prediction (MLPC) where the complex excitation is constructed from a set of several pulses, residual excited linear prediction (RELP) where the error signal or residual is used as an excitation signal and the speech signal can be reconstructed exactly, and code excited linear prediction (CELP) where a finite number of excitations used are stored in a finite codebook (Campos et al. 1996).
5.5 Sinusoidal Models
Sinusoidal models are based on a well known assumption that the speech signal can be represented as a sum of sine waves with time-varying amplitudes and frequencies (McAulay et al. 1986, Macon 1996, Kleijn et al. 1998). In the basic model, the speech signal s(n) is modeled as the sum of a small number L of sinusoids
![]() ,
,
where Al(n) and f l(n) represent the amplitude and phase of each sinusoidal component associated with the frequency track w l. To find these parameters Al(n) and f l(n), the DFT of windowed signal frames is calculated, and the peaks of the spectral magnitude are selected from each frame (see Figure 5.6). The basic model is also known as the McAulay/Quatieri Model. The basic model has also some modifications such as ABS/OLA (Analysis by Synthesis / Overlap Add) and Hybrid / Sinusoidal Noise models (Macon 1996).
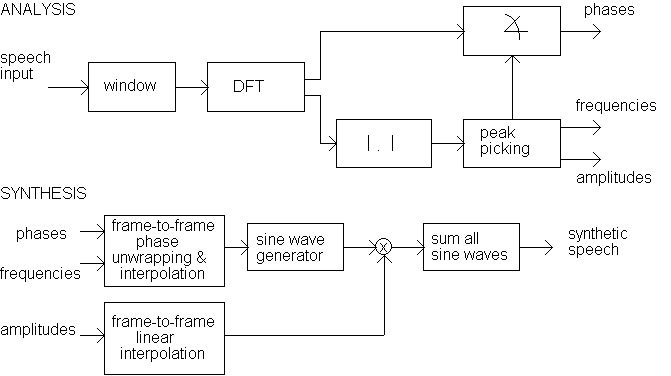
Fig. 5.6. Sinusoidal analysis / synthesis system (Macon 1996).
While the sinusoidal models are perhaps very suitable for representing periodic signals, such as vowels and voiced consonants, the representation of unvoiced speech becomes problematic (Macon 1996).
Sinusoidal models are also used successfully in singing voice synthesis (Macon 1996, Macon et al. 1997). The synthesis of singing differs from speech synthesis in many ways. In singing, the intelligibility of the phonemic message is often secondary to the intonation and musical qualities. Vowels are usually sustained longer in singing than in normal speech, and naturally, easy and independent controlling of pitch and loudness is also required. The best known singing synthesis system is perhaps the LYRICOS which is developed at Georgia Institute of Technology. The system uses sinusoidal-modeled segments from an inventory of singing voice data collected from human vocalist maintaining the characteristics and perceived identity. The system uses a standard MIDI-interface where the user specifies a musical score, phonetically-spelled lyrics, and control parameters such as vibrato and vocal effort (Macon et al. 1997).
5.6 High-Level Synthesis
With high-level synthesis the input text or information is transcribed in such format that low-level voice synthesizer is capable to produce the acoustic output. A proper implementation of this is the fundamental challenge in all present systems and will probably be for years to come. The procedure consists of three main phases.
After high-level synthesizer, the information is delivered to drive some low-level system. The type of used data depends on the driven system. For example, for formant synthesizer, at least fundamental frequency, formant frequencies, duration, and amplitude of each sound segment is needed.
5.6.1 Text Preprocessing
The first task of all TTS systems is to convert input data to proper form for a synthesizer. In this stage, all non-alphabetical characters, numbers, abbreviations, and acronyms must be converted into a full spelled-out format. Text preprocessing is usually made with simple one-to-one lookup tables, but in some cases additional information of neighboring words or characters is needed. This may lead to a large database and complicated set of rules and may cause some problems with real-time systems. Input text may also contain some control characters which must be delivered through the text parser without modifications. The conversion must neither affect abbreviations which are a part of another. For example, if the character M is in some context converted as mega, the abbreviation MTV should not be converted as megaTV. However, character strings or abbreviations which are not in a lookup table and consist only of consonants can be always converted letter-by-letter because those kind of words do no exist in any language.
Numbers are perhaps the most difficult to convert correctly into spelled-out format. Numbers are used in several relations, such as digits, dates, roman numerals, measures, and mathematical expressions. Numbers between 1100 and 1999 are usually converted as years like 1910 as nineteen-ten. Expressions in form 12/12/99 or 11/11/1999 may be converted as dates, if the numbers are within acceptable values. However, the expression 2/5 is more difficult because it may be either two divided by five or the second of may. In some cases, the correct conversion is possible to conclude from compounding information (measures etc.) or from the length of the number (dates, phone numbers etc.). However, there will be always some ambiguous situations.
In some cases with measures, usually currencies, the order of some character and value is changed. For example $3.02 is converted as three dollars and two cents. In these situations, the numerical expressions which are already in spelled-out format must be recognized to avoid the misconversion like $100 million to one hundred dollars million.
Some abbreviations and acronyms are ambiguous in different context like described in Chapter 4. For common abbreviation like st., the first thing to do is to check if it is followed by a capitalized word (potential name), when it will be expanded as saint. Otherwise, if it is preceded a capitalized word, an alphanumeric (5th), or a number, it will be expanded as street (Kleijn et al. 1998).
The parser may be implemented by straight programming using for example C, LISP or PERL or a parsing database with separate interface may be used. The latter method provides more flexibility for corrections afterwards but may have some limitations with abbreviations which have several different versions of correct conversion. A line in a converting database may look like for example following:
<"rules", "abbrev", "preceding info", "following info", "converted abbreviation">
where the "rules" may contain information of in which cases the current abbreviation is converted, e.g., if it is accepted in capitalized form or accepted with period or colon. Preceding and following information may contain also the accepted forms of ambient text, such as numbers, spaces, and character characteristics (vowel/consonant, capitalized etc.).
Sometimes different special modes, especially with numbers, are used to make this stage more accurate, for example, math mode for mathematical expressions and date mode for dates and so on. Another situation where the specific rules are needed is for example the E-mail messages where the header information needs special attention.
5.6.2 Pronunciation
Analysis for correct pronunciation from written text has also been one of the most challenging tasks in speech synthesis field. Especially, with some telephony applications where almost all words are common names or street addresses. One method is to store as much names as possible into a specific pronunciation table. Due to the amount of excisting names, this is quite unreasonable. So rule-based system with an exception dictionary for words that fail with those letter-to-phoneme rules may be a much more reasonable approach (Belhoula et al. 1993). This approach is also suitable for normal pronunciation analysis. With morphemic analysis, a certain word can be divided in several independed parts which are considered as the minimal meaningful subpart of words as prefix, root, and affix. About 12 000 morphemes are needed for covering 95 percent of English (Allen et al.1987). However, the morphemic analysis may fail with word pairs, such as heal/health or sign/signal (Klatt 1987).
Another perhaps relatively good approach to the pronunciation problem is a method called pronunciation by analogy where a novel word is recognized as parts of the known words and the part pronunciations are built up to produce the pronunciation of a new word, for example pronunciation of word grip may be constructed from grin and rip (Gaved 1993). In some situations, such as speech markup languages described later in Chapter 7, information of correct pronunciation may be given separately.
5.6.3 Prosody
Prosodic or suprasegmental features consist of pitch, duration, and stress over the time. With good controlling of these gender, age, emotions, and other features in speech can be well modeled. However, almost everything seems to have effect on prosodic features of natural speech which makes accurate modeling very difficult. Prosodic features can be divided into several levels such as syllable, word, or phrase level. For example, at word level vowels are more intense than consonants. At phrase level correct prosody is more difficult to produce than at the word level.
The pitch pattern or fundamental frequency over a sentence (intonation) in natural speech is a combination of many factors. The pitch contour depends on the meaning of the sentence. For example, in normal speech the pitch slightly decreases toward the end of the sentence and when the sentence is in a question form, the pitch pattern will raise to the end of sentence. In the end of sentence there may also be a continuation rise which indicates that there is more speech to come. A raise or fall in fundamental frequency can also indicate a stressed syllable (Klatt 1987, Donovan 1996). Finally, the pitch contour is also affected by gender, physical and emotional state, and attitude of the speaker.
The duration or time characteristics can also be investigated at several levels from phoneme (segmental) durations to sentence level timing, speaking rate, and rhythm. The segmental duration is determined by a set of rules to determine correct timing. Usually some inherent duration for phoneme is modified by rules between maximum and minimum durations. For example, consonants in non-word-initial position are shortened, emphasized words are significantly lengthened, or a stressed vowel or sonorant preceded by a voiceless plosive is lengthened (Klatt 1987, Allen et al. 1987). In general, the phoneme duration differs due to neighboring phonemes. At sentence level, the speech rate, rhythm, and correct placing of pauses for correct phrase boundaries are important. For example, a missing phrase boundary just makes speech sound rushed which is not as bad as an extra boundary which can be confusing (Donovan 1996). With some methods to control duration or fundamental frequency, such as the PSOLA method, the manipulation of one feature affects to another (Kortekaas et al. 1997).
The intensity pattern is perceived as a loudness of speech over the time. At syllable level vowels are usually more intense than consonants and at a phrase level syllables at the end of an utterance can become weaker in intensity. The intensity pattern in speech is highly related with fundamental frequency. The intensity of a voiced sound goes up in proportion to fundamental frequency (Klatt 1987).
The speaker's feelings and emotional state affect speech in many ways and the proper implementation of these features in synthesized speech may increase the quality considerably. With text-to-speech systems this is rather difficult because written text usually contains no information of these features. However, this kind of information may be provided to a synthesizer with some specific control characters or character strings. These methods are described later in Chapter 7. The users of speech synthesizers may also need to express their feelings in "real-time". For example, deafened people can not express their feelings when communicating with speech synthesizer through a telephone line. Emotions may also be controlled by specific software to control synthesizer parameters. Such system is for example HAMLET (Helpful Automatic Machine for Language and Emotional Talk) which drives the commercial DECtalk synthesizer (Abadjieva et al. 1993, Murray et al. 1996).
This section shortly introduces how some basic emotional states affect voice characteristics. The voice parameters affected by emotions are usually categorized in three main types (Abadjieva et al. 1993, Murray et al. 1993):
The number of possible emotions is very large, but there are five discrete emotional states which are commonly referred as the primary or basic emotions and the others are altered or mixed forms of these (Abadjieva et al. 1993). These are anger, happiness, sadness, fear, and disgust. The secondary emotional states are for example whispering, shouting, grief, and tiredness.
Anger in speech causes increased intensity with dynamic changes (Scherer 1996). The voice is very breathy and has tense articulation with abrupt changes. The average pitch pattern is higher and there is a strong downward inflection at the end of the sentence. The pitch range and its variations are also wider than in normal speech and the average speech rate is also a little bit faster.
Happiness or joy causes slightly increased intensity and articulation for content words. The voice is breathy and light without tension. Happiness also leads to increase in pitch and pitch range. The peak values of pitch and the speech rate are the highest of basic emotions.
Fear or anxiety makes the intensity of speech lower with no dynamic changes. Articulation is precise and the voice is irregular and energy at lower frequencies is reduced. The average pitch and pitch range are slightly higher than in neutral speech. The speech rate is slightly faster than in normal speech and contains pauses between words forming almost one third of the total speaking time (Murray et al. 1993, Abadjieva et al. 1993).
Sadness or sorrowness in speech decreases the speech intensity and its dynamic changes. The average pitch is at the same level as in neutral speech, but there are almost no dynamic changes. The articulation precision and the speech rate are also decreased. High ratio of pauses to phonation time also occurs (Cowie et al. 1996). Grief is an extreme form of sadness where the average pitch is lowered and the pitch range is very narrow. Speech rate is very slow and pauses form almost a half of the total speaking time (Murray et al. 1993).
Disgust or contempt in speech also decreases the speech intensity and its dynamic range. The average pitch level and the speech rate are also lower compared to normal speech and the number of pauses is high. Articulation precision and phonation time are increased and the stressed syllables in stressed content words are lengthened (Abadjieva et al. 1993).
Whispering and shouting are also common versions of expression. Whispering is produced by speaking with high breathiness without fundamental frequency, but the emotions can still be conveyed (Murray et al. 1993). Shouted speech causes an increased pitch range, intensity and greater variability in it. Tiredness causes a loss of elasticity of articulatory muscles leading to lower voice and narrow pitch range.
5.7 Other Methods and Techniques
Several other methods and experiments to improve the quality of synthetic speech have been made. Variations and combinations of previously described methods have been studied widely, but there is still no single method to be considered distinctly the best. Synthesized speech can also be manipulated afterwards with normal speech processing algorithms. For example, adding some echo may produce more pleasant speech. However, this approach may easily increase the computational load of the system.
Some experiments to show the use of a combination of the basic synthesis methods have been made, because different methods show different success in generating individual phonemes. Time domain synthesis can produce high-quality and natural sounding speech segments, but in some segment combinations the synthesized speech is discontinuous at the segment boundaries and if a wide-range variation of fundamental frequency is required, overall complexity will increase. On the other hand, formant synthesis yields more homogeneous speech allowing a good control of fundamental frequency, but the voice-timbre sounds more synthetic. This approach leads to the hybrid system which combines the time- and frequency-domain methods. The basic idea of a hybrid system is shown in Figure 5.7 (Fries 1993).
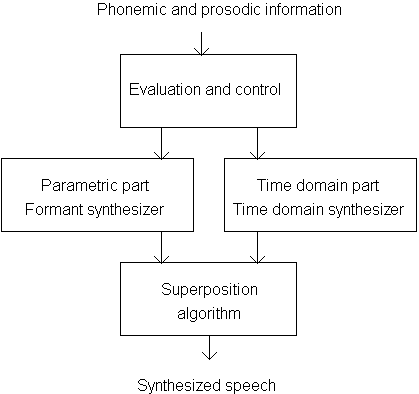
Fig. 5.7. Basic idea of the hybrid synthesis system
Several methods and techniques for determining the control parameters for a synthesizer may be used. Recently, the artificial intelligence based methods, such as Artificial Neural Networks (ANN), have been used to control synthesis parameters, such as duration, gain, and fundamental frequency (Scordilis et al. 1989, Karjalainen et al. 1991, 1998). Neural networks have been applied in speech synthesis for about ten years and they use a set of processing elements or nodes analogous to neurons in the brain. These processing elements are interconnected in a network that can identify patterns in data as it is exposed to the data. An example of using neural networks with WLP-based speech synthesis is given in Figure 5.8.
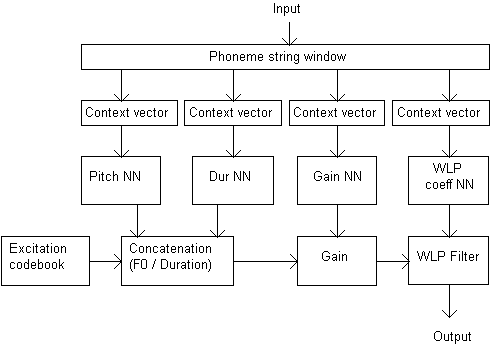
Fig. 5.8. An example of using neural networks in WLP synthesis (Karjalainen et al. 1998).
For more detailed discussion of using neural networks in speech synthesis, see for example (Rahim et al. 1993), (Cawley et al. 1993a, 1993b), (Cawley 1996), or (Karjalainen et al. 1991, 1998) and references in them.
Another common method in speech synthesis, and especially in speech recognition and analysis of prosodic parameters from speech, is for example the use of hidden Markov models (HMMs). The method is based on a statistical approach to simulate real life stochastic processes (Rentzepopoulos et al. 1992). A hidden Markov model is a collection of states connected by transitions. Each transition carries two sets of probabilities: a transition probability, which provides the probability for taking the transition, and an output probability density function, which defines the conditional probability of emitting each output symbol from a finite alphabet, given that that the transition is taken (Lee 1989).